New Perspectives Blog Series – 3 Key SAP HANA Embedded Analytics Challenges

3 Key SAP HANA Embedded Analytics Challenges
Welcome to TruQua’s New Perspectives blog series. This blog series provides a platform for our consultants to share their perspectives, insights, and experiences on emerging technologies such as SAP HANA and SAP Analytics Cloud.
This week we are going to be speaking with Laura Rossi. Laura is a Consultant at TruQua, specializing in using the Embedded Analytics capabilities of SAP HANA to provide tremendous reporting and planning value in SAP S/4HANA and SAP Analytics Cloud (SAC). Today Laura and I are going to discuss three key SAP HANA challenges that customers face, and how to overcome them.
These challenges come from mature implementations where TruQua was first engaged post-go-live to assist the customer. We want to cover not only the fix but the root cause of the issues which were presented and how we ensured the customer’s challenges did not return.
Challenge 1 – HANA’s Enormous Throughput

JS Irick: Without hyperbole, HANA is the tool that many data scientists and financial analysts have waited their entire careers for. HANA easily handles the Universal Journal – billions of records with 300+ columns, condensing hundreds of ERP tables into a single flat structure.
With that exceptional power comes risk – in the case of one engagement, we found that a single query required 700 Gigabytes of memory; at another customer, billions of records were passed to the SAP NetWeaver layer, repeatedly threatening productive stability.
From both a development and testing perspective, how do you recommend customers effectively harness HANA’s strengths?
Laura Rossi: As you mentioned, JS, HANA has the capacity to process massive tables in a matter of seconds, allowing users to build large, complex views on their data, add calculations, filter, reformat, etc. and store them as a single flat structure. However, the fact that we can create large, complex queries doesn’t necessarily mean we should leverage that power at every turn. Inefficiencies compound quickly, which leads to the sort of memory demands that overload and crash systems, especially if we’re talking about sandbox or test scenarios with limited memory allocations. At my most recent client, a single inefficient query managed to slow down our development system very noticeably until we identified and redesigned it. A couple of hours redesigning the culprit query converted an often-crashing, very slow query into a process that now runs in about a minute.
Certain modeling requirements require large, memory consuming queries, which HANA can handle. The important thing is to not compound unnecessary demands around the real, necessary demands. Nobody wants to wait for 15 minutes to run a query that could be accomplished in 1.5.
Besides, some optimizations are simple and based on classic database design principles. For instance, instead of stringing a number of outer joins to attribute sparse details, the same scenario can be broken down into different cases based on how the attribution changes, what attributes apply, which don’t, and how they are managed with inner joins and filters. If a complex selection criterion requires a join or a transposition, it is worth spending some time to evaluate if another form of detail or calculation can serve the same purpose. That way, when a requirement needs to be addressed that necessitates a large amount of memory, we’re inserting those memory demands on top of the leanest, most efficient model possible rather than compounding inefficiency.
JS Irick: You’ve touched on a really interesting point here, which is the fundamental conflict between “for purpose views” and a “view as data warehouse”. The former can survive a filtering issue or two, but the later requires perfection across the entire stack. Aside from the obvious semantic advantages from using Core Data Service (CDS) views, the very fact that they put some more guard rails and rigor around HANA views make them a very attractive option for ensuring stability.
From a pragmatic perspective, I’m a big proponent of productive volume (not data, but volume) in development. For complex queries, you have to be able to really see the impact.
Laura Rossi: I agree. Again, at my last client, we were lucky to have a large data sample within a relatively low-memory sandbox system. I’m calling this lucky because it allowed our team to design keeping simplicity and efficiency in mind from day one, rather than building everything and then optimizing. The thing with HANA is, it’s powerful enough that it will most likely still run the inefficient query. But again, that doesn’t mean it should. Another useful feature is HANA’s SQL console allowing you to analyze the memory demand or “subtree cost” of a view and all its subcomponents.
Challenge 2 – Lack of “HANA Gurus”
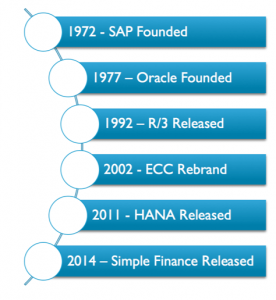 JS Irick: For nearly 40 years, SAP was database agnostic, with best practices ensuring that SAP experts stayed in the application layer.
JS Irick: For nearly 40 years, SAP was database agnostic, with best practices ensuring that SAP experts stayed in the application layer.
This firewall, which was only possible thanks to the excellent integration layer between NetWeaver and the database has vanished. Now we have an unparalleled development environment for semantically enriched financial data. We also have incredibly talented teams, with a deep understanding of their organizations’ processes and needs, but for whom database development has been intentionally locked away for two generations.
What was critical for you to become so strong in HANA development, and how do you work with experienced customer teams to enable them in this new space?
Laura Rossi: A lot of the SAP landscape is evolving. SAC and S/4HANA are reshaping how we conceive solutions and what clients choose to prioritize. So, I would argue that now is the best time to start learning and relearning. Of course, S/4HANA is built on HANA, but even in a case like SAC, connecting to a HANA database is easy and can significantly increase the performance capabilities of the reporting solution.
And while it’s true that we can’t leverage the amount of experience that is available for other older SAP solutions, best practices of data analyses can still be adapted and leveraged into best business solutions for modeling in HANA.
JS Irick: I love the positivity! The most rewarding part of working in consulting is seeing the customer teams you work with gain new abilities (and recognition). “Now is the best time to start learning and relearning,” says it all.
In terms of where to start, from a functional perspective, I always recommend finding that next step. You’re not looking to reinvent FP&A, you’re looking to bring in new abilities to your existing expertise. Keep building on your strengths. From a technical perspective, I recommend customers learn the same way we learn at TruQua. You have to be able to leverage the plan-visualizer and truly understand how the platform is running your queries. Small tweaks at the modeling level can have an incredible impact, you need to be able to understand where the bottlenecks are to be able to solve them.
Laura Rossi: Definitely agree on the plan visualizer, it’s a great place to start diagnosing the aspects of a redesign which will have the most productive impact. Similarly, understanding the lineage of your data and which stage of a view or model some calculation is performed at, and why, should probably be the first few steps. Besides that, so long as we keep a lean design in mind, I like to argue that the simpler the better, both from a future troubleshooting point of view as well as from a scalability perspective.
Challenge 3 – The Complexities of Real-Time Transformation
JS Irick: I don’t think it’s a stretch to consider the path from the database to a report a closed system. The ETL (Extract, Transform, Load) process and the many aggregations, enrichment, and conversion layers have disappeared with the move to S/4HANA and embedded analytics, but the complexity hasn’t vanished, it’s still present in your CDS or Native HANA views.
The standard reporting questions still exist, but now they sit inside a single view instead of a complex architecture diagram:
- How do we cache data?
- What do we need to persist?
- How do we handle configuration?
- Where are the extensibility points for new requirements?
- How are master data/hierarchy changes handled?
How do you address these challenges with customers, and how do you ensure that your solution is one they can own and expand?
Laura Rossi: In a sense, I think all of the questions we’re addressing today come down to the same principles of a lean, efficient design. Being very clear on requirements, what may or may not change, what has changed historically and where everything resides is key, so in that sense one should start at the very basics: taking a good look at what’s required and at what the data looks like for current actuals, planning, and historical data.
After this, breaking down the views modeling into use-case or scenario-based “layers” helps both from the point of view of traceability and simple troubleshooting while also keeping the complexity low. In other words, I’d recommend building multiple views for different aspects of the business use and then a “top node” view that combines the result of these smaller layers. A simple and efficient view with a clear use case is easier to build upon and expand that a large, complex view that mixes multiple use case scenarios.
JS Irick: I really like that you’ve presented a layered architecture from a functional perspective. (also that you made a sly nod to agile/lean development).
A developer needs to truly understand the customer use case, be able to communicate to the user, and build towards the need, not the requirement. Then to go above and beyond, you must understand how the business needs may change over time, or you’re left with a brittle solution.
There are so many places to leave hooks for extension and configuration – web frontend, XSA, via the BW layer, etc. I’d be hesitant to make a hard and fast rule about where these points should be. Change management from a technical perspective rarely gets any shine, but it really pays to keep as much as possible “in the customer’s language” so to speak.
Laura Rossi: I agree. Personally, I think understanding the business case and “business language” for everything I’ve built has been an area where I’ve had to learn the most while working with TruQua, and it has really paid off. The best solution can only shine if the users have an understanding and need for it. And of course, having a full grasp of the use case from the beginning saves you a lot of rework in Q&A. Ultimately, the solution should work for the client.
Conclusion
JS Irick: Thanks so much for sharing your perspective today, Laura. The emerging technologies in the SAP landscape – including HANA, SAP Analytics Cloud, Leonardo, and S/4HANA are providing an opportunity for early career consultants to deliver tremendous value. I’m glad we got a little bit of time today to discuss how you are helping customers conquer their biggest challenges. Thanks for sharing your insights, and I’m looking forward to speaking again sometime soon!
Laura Rossi: Thank you for the opportunity to share! This is definitely an exciting time to be in the SAP ecosystem and conversations like this one create great opportunities for the growth and sharing of ideas. I’ve definitely learned a lot from everyone else at TruQua, so it’s great to join the conversation.
About our contributors:
JS Irick has the best job in the world; working with a talented team to solve the toughest business challenges. JS is an internationally recognized speaker on the topics of Machine Learning, SAP Planning, SAP S/4HANA and Software development. As the Director of Data Science and Artificial Intelligence at TruQua, JS has built best practices for SAP implementations in the areas of SAP HANA, SAP S/4HANA reporting, and SAP S/4HANA customization.
Laura Rossi is an SAP Consultant at TruQua who specializes in applying Data Science to financial planning and analysis. Laura is highly skilled in developing native database applications to solve not only the customer’s current challenges but anticipate and adapt to their future goals. Laura’s work in the “modern planning stack” of SAP HANA, SAP S/4HANA and SAP Analytics Cloud helps provides a base for Collaborative Enterprise Planning.
Thank you for reading our first installment in our New Perspectives blog series. Stay tuned for our next post which will feature Andrew Xue, SAP Consultant and his insights into Collaborative Enterprise Planning.
For more information on TruQua’s services and offerings, visit us online at www.truqua.com. To be notified of future blog posts and be included on our email list, please complete the form below.