New Perspectives Blog Series: Bringing AI to the Realm of Corporate Finance

Bringing AI to the Realm of Corporate Finance
Welcome to TruQua’s New Perspectives blog series. This blog series provides a platform for our consultants to share their perspectives, insights, and experiences on emerging technologies such as SAP HANA and SAP Analytics Cloud.
Today we are speaking with Senior Cloud Architect Daniel Settanni. Daniel’s passion is bringing AI to the realm of corporate finance. With his deep expertise in time series analysis, cloud architecture and SAP planning solutions, Daniel is able to not only create impressive Machine Learning models but also deploy them in an integrated, accurate and explainable way. As you will see below, Daniel does an exceptional job at both demystifying the technologies behind AI/ML and “defeating the black box” through explainable AI.
Perspective 1: Getting Started with Machine Learning for Finance

JS Irick: Daniel, a few weeks back you and I hosted a pre-conference session at SAP-Centric where we led attendees through building their first Machine Learning model to predict OPEX (based on published financials for a Fortune 500 company). In that case, it was easy for our attendees to be successful because the problem was already defined. When it comes to the enterprise level, identifying the opportunity and success criteria is the first major roadblock customers face. Can you talk a little bit about how customers can set themselves up for success in their foundational ML projects?
Daniel Settanni: Sure JS. Figuring out where to start with ML can seem like an insurmountable challenge and for good reason. ML and AI pop up in the news every day. Topics like ML generated movie recommendations and AI created art are cool, but not relatable to most enterprises. On the flip side, Enterprise Software usually incorporates ML/AI in tasks that are common across wide swaths of the market that focus on automation. These are much more relatable, but don’t speak to how Enterprises can use ML to solve their own problems… from the mundane to the highly strategic.
So, now to your question.
If an Enterprise is just starting out with Machine Learning and is having a hard time finding the right opportunity, then pick something relatively simple like a basic forecasting project. These are a great place to start because the models can be kept simple, the predictions can be easily integrated with the existing business processes, and the results deliver real value (I haven’t met an Enterprise yet that isn’t looking to improve their forecasting accuracy in one area or another). But above all, projects like this provide real-world experience with the ins and outs of ML – plus they always generate a ton of new ideas on where to use ML next.
If the Enterprise has already identified the opportunity, then I’d make sure that their success criteria include delivering a way for users to interact with the model. This could be as simple as pulling predictions into an existing business system as a new Forecast version or entail developing a custom dashboard for what-if analysis. In any case, if the success criteria is simply to build an accurate model that never sees the world beyond the data science team, they will be losing out on the vast majority of ML’s true Enterprise value.
JS Irick: “But above all, projects like this provide real-world experience with the ins and outs of ML – plus they always generate a ton of new ideas on where to use ML next.” That’s definitely my favorite part of working on these projects with you. We get to see the lightbulb go on in real time which leads to fascinating strategic discussions. I believe that best consultants not only help their clients with their current project, but they also help chart the way forward through education and enablement.
Can you talk a bit more about “interacting with the model”, with some examples? I think this is important for folks just getting started with AI/ML.
Daniel Settanni: Absolutely. The main point here is that the more completely people can interact with something (an ML model in this case), the more they will understand it and the greater the understanding, the greater the potential for meaningful insights.
This “interaction” can look very different depending on the business problem being solved.
For example, if we built out a Forecasting model the minimum level of interaction would result in a spreadsheet. This isn’t a great option for a lot of reasons, the most basic of which is that it’s not in the same place as the related business data.
We can fix that by integrating our hypothetical Forecasting model with the related Enterprise Application. Now the forecasts can be viewed in context, but there isn’t any transparency around how the model came to the conclusions it did. The best case here is that the forecast is proved to be accurate at which point the business will just accept it – but being overly reliant on a model in this way is dangerous.
So, next, we’ll add explainability to our model. Based on this, our analysts gain insight into not only what the model predicted, but what why it arrived at the answer as well. Since our analysts are the true experts, this can lead to valuable feedback on ways to make the model better. Because there’s transparency, it can also become more of a trusted tool.
We’ve made a lot of progress from our spreadsheet, but we don’t have to stop there. We could make the model truly interactive by allowing analysts to tweak its assumptions and see its impacts on the prediction and explanations. At this point, you have what I like to call a Strategic model, one that can aid in making business decisions.
Before moving on, I’d like to highlight another example to show how this methodology can be applied to other areas. As you know, we built out an Employee Retention model last year that was integrated with SuccessFactors. The basic output of the model was the likelihood an employee would leave during the next year. The predictions were based on factors like salary growth, time at the company, historical promotions, etc.
To make this model most valuable, we didn’t stop at the raw prediction. We created a dashboard where HR analysts could actually predict the impact of interventions, greatly increasing the chance they could retain their top talent.
These are just a few examples of why I believe interaction is one of the core pillars of a successful, and valuable, ML-based solution.
Perspective 2: From Prediction to Explanation to Intervention

JS Irick: From my work in medical science, I’ve always felt that researchers first seek to understand so that you can intervene. While the moment of discovery is exciting, it pales in comparison to using that discovery to impact change. Machine Learning changes the paradigm a bit, in that first you predict, then you explain, then you intervene. This leads to two questions – first, how do you get predictions into analysts’ hands quickly enough so that there is time to intervene? Second, can you explain to our readers how you go from a raw numerical prediction to actionable insights?
Daniel Settanni: You bring up some great points here. Without insight, there can be no action and without action, there can be no value.
The answer to the first question is easy to answer, but not always simple to implement. To get predictions into Analysts hands quickly enough to intervene, a model must either be integrated with their business system or directly accessible in some other way. If Analysts have to wait for quarterly or even monthly reports, then they’ve probably missed their chance to act. On the other hand, allowing them to perform some degree of what-if analysis in real time can put them dramatically ahead of the curve.
One quick anecdote before I move on to question number two… in my experience, the initial success criteria for an ML project is accuracy. This makes complete and total sense but once you deliver an accurate model the next logical question is “Why”? No one likes a black box, and even more importantly, no one trusts a black box. Without some degree of understanding, trusting the results of an ML model can feel like a leap of faith and who wants to bet their career on that?
So how do you get from raw numerical predictions to actionable insights? It starts with deeply understanding the problem you are trying to solve and building your model around that (instead of just accuracy). This involves carefully selecting features (model inputs) that are related to the question at hand. Having relatable features can give analysts some confidence in a model, but adding in Explainable AI, a technology that figures out each features contribution to a prediction, can really deliver the trust needed to go from prediction to action.
JS Irick: Without getting too deep into the technical side, can you talk a bit more about feature selection? In a lot of ways, I lean on my research experience; which means I focus on explaining statistical malpractice “this will pollute your results because….”. I’d love to hear a positive, actionable take on the value of feature selection.
Daniel Settanni: You’ve picked a topic close to my heart. Before diving in, here’s a quick recap on what a feature is. In its most basic form, a Machine Learning model uses a bunch of inputs to predict an output. In Data Science lingo the inputs are called features and the output is called the label.
There’s one more topic we need to touch on before we can really talk about features… the different reasons models are created in the first place. This may sound like a silly question – we create models to predict things of course!
But… there are different types of predictions.
For example, I may want to create a model that can remove human bias from my Sales forecasts, or I may want a model that can accurately predict the impact of a certain business decision to my Sales forecast. In both cases, we’re forecasting the same thing, but our goals are very different.
How can we do this? The answer lies in feature selection.
In the first scenario (where we want to remove human bias), we would focus on factors outside the scope of control of the business. These would likely include macroeconomic data, sales trends, consumer (financial) health, and the like. By training a model with this type of features, we would be capturing the historic performance of a company. These types of models tend to be very accurate, especially for mature organizations.
In the second scenario, we want to do pretty much the opposite. Instead of focusing on things we can’t change to capture historical performance, we look at the things we can – so it’s much more of a microeconomic viewpoint. By adding explanations to the solution, a model like this can empower decision makers to get accurate information on the impacts to the bottom line of many decisions. That said, this model is going to be extremely vulnerable to human bias so while it can be an amazing strategic solution, it isn’t a great pure forecasting one.
And there’s no law that says all features have to be macro vs microeconomic. In fact, many are mashups if you will. So ultimately the key isn’t to match the features to what you’re predicting, it’s to match the features to the question you’re trying to answer.
Perspective 3: Into the Wild

JS Irick: As you know, many wonderful forecasting tools never make it out of the “validation” phase. Integration, maintenance, retraining, and continuous validation are critical for the long term health of any project, but especially an ML/AI project. Unsupervised predictive models tend to fail “silently”, in that there’s no production down moment. Our product Florence is one way for customers to ensure not only the best practices in model development but also long term model health. Can you talk a little bit about the challenges customers face and how Florence solves them?
Daniel Settanni: Glad to. ML/AI projects often focus, in some cases solely, on building an accurate model. This is a fine approach if you’re in a scientific setting, but in the Enterprise simply building the model is only a small piece of the puzzle.
To get the most value out of an Enterprise ML project, it has to be:
- Accurate
- Interactable
- Explainable
A model alone can only deliver on accuracy.
To be interactable, the model has to be accessible in real-time. This means it has to be deployed somewhere and either integrated into an existing system or a net new application has to be created.
To be explainable, the appropriate technology must be deployed alongside the model and integrated into the prediction process.
The challenges that come with making a model interactable and explainable are considerable and often require ongoing collaboration with the DevOps and Development teams. I highlighted “ongoing collaboration” because this is commonly missed cost/risk. During the lifetime of an ML/AI project, its’ model(s) will likely have to be retrained many times. When a model gets retrained, the data preparation steps often have to update, and when that happens corresponding changes have to be made by the DevOps and Development teams. The worst part is if the changes aren’t made exactly right the models will keep on delivering predictions. They’ll just be less accurate, probably way less accurate. And if you’re making decisions off of those predictions, that could be very costly.
Most solutions only deliver on a few pieces of an ML/AI project, leaving it up to each customer to figure out everything else. We took a very different approach with Florence.
Florence covers the entire process, from creating accurate and explainable models to make them available in real-time, to provide the APIs and security necessary to integrate with practically any Enterprise system.
One of my favorite technological advances is the way Florence abstracts away things like data preparation, so all the Developers have to focus on is creating the best user experience and users can be confident that predictions aren’t wrong due to integration issues.
JS Irick: Excellently put. I’m a big believer in Eric Raymond’s “The Art of Unix Programming”. I find that the rules still hold up (also, it’s interesting that some of the proto-ML techniques are coming back into vogue). Some of the rules speak strongly to the strengths of ML – “Avoid hand-hacking; write programs to write programs when you can” and “Programmer time is expensive; conserve it in preference to machine time” come immediately to mind. However, you’ve touched on something that shoots up red flags – “When you must fail, fail noisily and as soon as possible”. Some of the toughest technical issues we face come when a system is failing silently, producing unintended consequences downstream. Especially when it comes to algorithms whose results are making financial decisions. Ask any futures trader, they’d rather the system crash than give incorrect responses due to a bug.
You hit the nail on the head when you noted that Florence applies the necessary data prep on the decision side as well as the training side. If numbers need to be scaled, normalized, etc. that should absolutely be on the server side. As a user, I get so salty when I hear things like “Oh, you forgot to turn your image into an array of integers before submitting it”. Let people speak in their language, and if there’s any data prep that needs to be done, it needs to be done in an abstracted, centralized way.
You’ve been doing some tremendous UX work in Florence recently, got a teaser for us?
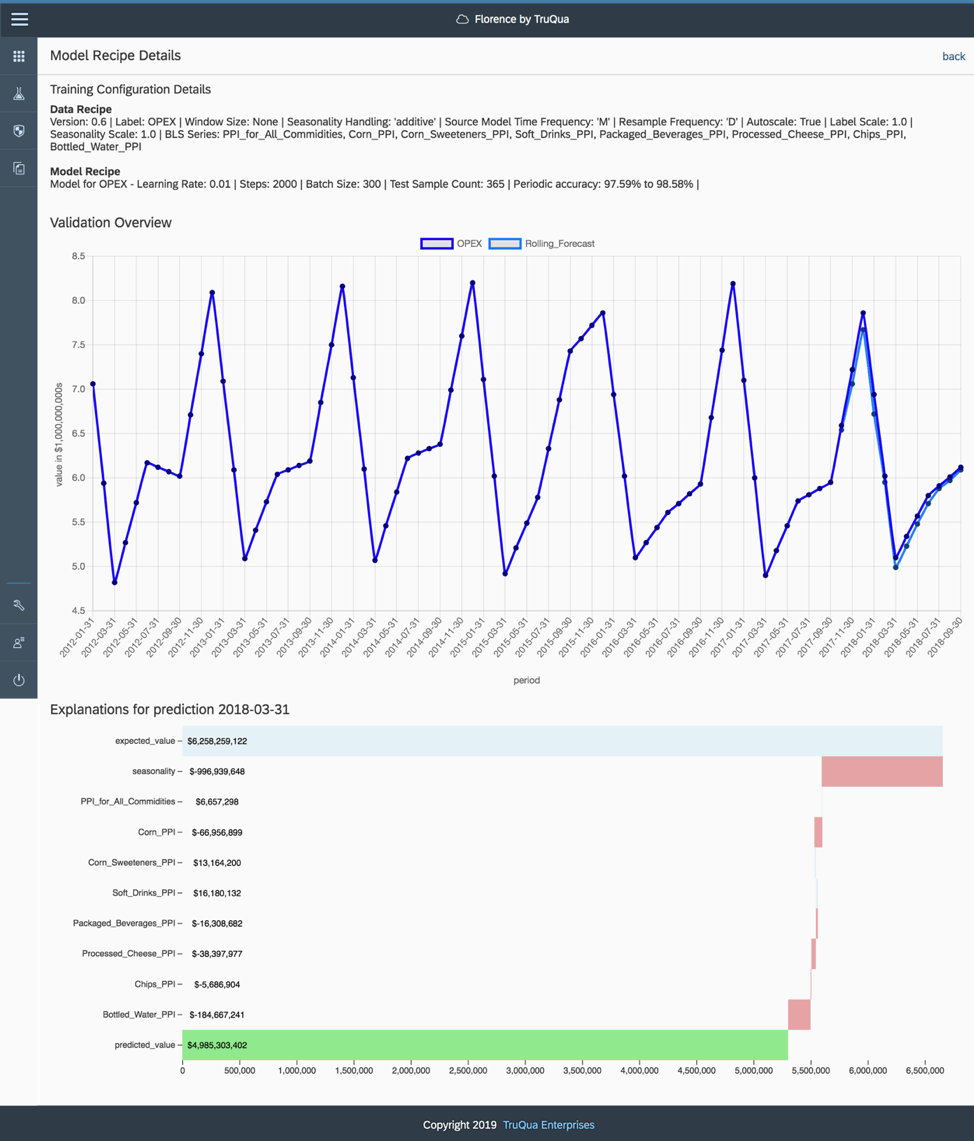
Daniel Settanni: I’ve got the perfect images for this conversation. It’s of Florence’s model validation view for a Macroeconomic model.
The first screenshot shows the incredible accuracy we obtained, but perhaps, more importantly, the explainability Florence delivers. Information like this can drive extremely valuable insights, and with Florence it doesn’t come with any additional work – it’s baked right in.
Thank you so much for spending time with me today Daniel. I always learn a tremendous amount when we speak, and even better, I get fired up to build new things. Hopefully, our readers were both educated and inspired as well.
Daniel and I consistently share articles/podcasts/news on AI/ML topics, and we’d love it if you all joined the conversation. Be on the lookout for our upcoming weekly newsletter which will go over the most interesting content of the week.
About our contributors:
JS Irick has the best job in the world; working with a talented team to solve the toughest business challenges. JS is an internationally recognized speaker on the topics of Machine Learning, SAP Planning, SAP S/4HANA and Software development. As the Director of Data Science and Artificial Intelligence at TruQua, JS has built best practices for SAP implementations in the areas of SAP HANA, SAP S/4HANA reporting, and SAP S/4HANA customization.
Daniel Settanni is living the dream at TruQua, using innovative technology to solve traditionally underserved Enterprise challenges. Making advanced technology more accessible with thoughtful design has been Daniel’s passion for years. He’s currently focused on Florence by TruQua, an innovative Machine Learning solution that delivers Interactive and Explainable AI in a fraction of the time, and cost, of any other product on the market.
Thank you for reading this installment in our New Perspectives blog series. Stay tuned for our next post where we will be talking to Senior Consultant Matt Montes on Central Finance and the road to S/4HANA for mature organizations.
For more information on TruQua’s services and offerings, visit us online at www.truqua.com. To be notified of future blog posts and be included on our email list, please complete the form below.